
Base58
base58编码原理
和base64编码一样, base58编码也是将非可视化字符可视化, 但不同的是base58去掉了: 0(数字零), O(大写字母O), I(大写字母I) 和
l(小写字母l), 和几个影响双击选择的字符, 如/, +。
字符集最终如下:
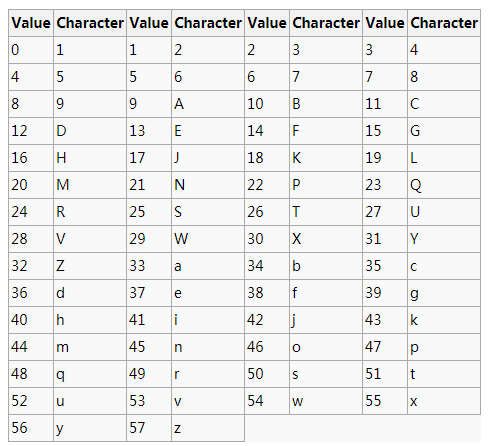
因为58 不是2的整次幂, 所以没有使用类似base64编码中使用直接截取3个字符转4个字符(38=46 , 2的6次方刚好64)的方法进行转换, 而是采用我们数学上经常使用的进制转换方法——辗转相除法。本质上, base64编码是64进制, base58是58进制
实例
如果将1234转换为58进制:
- 1234除以58, 商21, 余数16, 查表得H
- 21处以58, 商0, 余数21, 查表得N
最终得base58编码为NH
如果待转换的数前面有0怎么办?直接附加编码1来代表(编码表中1代表0)
加解密脚本
from binascii import * |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Lantern's 小站!
相关推荐




评论


