
Linux Kernel Basics
Kernel
Kernel 也是一个程序, 主要功能有两点
- 控制并与硬件交互
- 提供应用能运行的环境
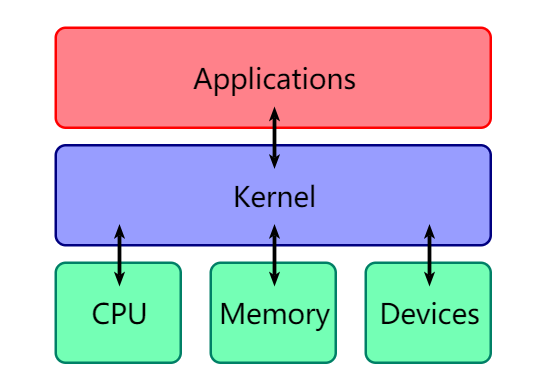
需要注意的是kernel的crash通常会引起重启
Ring Model
Intel CPU 将 CPU 的特权级别分为4个: Ring 0, Ring 1, Ring 2, Ring 3
Ring 0只给OS使用Ring 3所有程序都可以用- 内层Ring可以随意使用外层Ring资源
- 在
Ring 0下,可以修改用户的权限(也就是提权) - 大多数现代操作系统只用到了
Ring 0和Ring 3
Loadable Kernel Modules (LKMs)
可加载核心模块(或直接称为内核模块) 就像运行在内核空间的可执行程序,包括
- 驱动程序(
Device drivers)- 设备驱动
- 文件系统驱动
- ….
- 内核扩展模块(
modules)
LKMs的文件格式和用户态的可执行程序相同,Linux下为ELF,Windows下为EXE/DLL , mac下为MACH-O,因此可以用IDA等工具来分析内核模块, 文件后缀一般为.ko
模块可以被单独编译,但不能单独运行。它在运行是被链接到内核作为内核的一部分在内核空间运行,这与运行用户空间的进程不同。
模块通常用来实现一种文件系统、一个驱动程序或者其他内核上层的功能。
Linux 内核之所以提供模块机制,是以为它本身是一个单内核。单内核的优点是效率搞,因为所有内容都集合在一起,但缺点是可扩展性和可维护性相对较差,模块机制就是为了弥补这一缺陷。
相关指令
- insmod : 将指定模块加载到内核中
- rmmod : 从内核中卸载指定模块
- lsmod : 列出已加载模块
- modprobe : 添加或删除模块,modprobe在加载模块是会查找依赖关系
大多数 CTF 中的 kernel vulnerability 也出现在 LKM 中
syscall
系统调用,指用户空间的程序向操作系统内核请求需要更高权限的服务,例如IO操作或者进程间通讯。系统调用提供用户程序与操作系统间的接口,部分库函数(如 scanf , puts等IO相关的函数实际上是对系统调用(read 和 write) 的封装。
在
/usr/include/x86_64-linux-gnu/asm/unistd_64.h和/usr/include/x86_64-linux-gnu/asm/unistd_32.h分别可以查看64位和32位的系统调用号
- Linux Syscall Reference,可以查阅 32 位系统调用对应的寄存器含义以及源码。
- 64 位系统调用可以查看 Linux Syscall64 Reference
ioctl
系统调用,用于与设备通信
man ioctl |
直接查看man手册
int ioctl(int fd, unsigned long request, ...)的第一个参数为打开设备(open)返回的文件描述符, 第二个参数为用户程序对设备的控制命令,再后边的参数则是一些补充参数,与设备有关。
使用 ioctl 进行通信的原因:
操作系统提供了内核访问标准外部设备的系统调用,因为大多数硬件设备只能够在内核空间内直接寻址, 但是当访问非标准硬件设备这些系统调用显得不合适, 有时候用户模式可能需要直接访问设备。
比如,一个系统管理员可能要修改网卡的配置。现代操作系统提供了各种各样设备的支持,有一些设备可能没有被内核设计者考虑到,如此一来提供一个这样的系统调用来使用设备就变得不可能了。
为了解决这个问题,内核被设计成可扩展的,可以加入一个称为设备驱动的模块,驱动的代码允许在内核空间运行而且可以对设备直接寻址。一个 Ioctl 接口是一个独立的系统调用,通过它用户空间可以跟设备驱动沟通。对设备驱动的请求是一个以设备和请求号码为参数的 Ioctl 调用,如此内核就允许用户空间访问设备驱动进而访问设备而不需要了解具体的设备细节,同时也不需要一大堆针对不同设备的系统调用。
状态切换
user space to kernel space
通过
swapgs切换 GS 段寄存器,将 GS 寄存器值和一个特定位置的值进行交换,目的是保存 GS 值,同时将该位置的值作为内核执行时的 GS 值使用。将当前栈顶(用户空间栈顶)记录在 CPU 独占变量区域里,将 CPU 独占 区域里记录的内核栈顶放入 rsp/esp
通过 push 保存各寄存器值, 具体的代码如下:
ENTRY(entry_SYSCALL_64)
/* SWAPGS_UNSAFE_STACK是一个宏,x86直接定义为swapgs指令 */
SWAPGS_UNSAFE_STACK
/* 保存栈值,并设置内核栈 */
movq %rsp, PER_CPU_VAR(rsp_scratch)
movq PER_CPU_VAR(cpu_current_top_of_stack), %rsp
/* 通过push保存寄存器值,形成一个pt_regs结构 */
/* Construct struct pt_regs on stack */
pushq $__USER_DS /* pt_regs->ss */
pushq PER_CPU_VAR(rsp_scratch) /* pt_regs->sp */
pushq %r11 /* pt_regs->flags */
pushq $__USER_CS /* pt_regs->cs */
pushq %rcx /* pt_regs->ip */
pushq %rax /* pt_regs->orig_ax */
pushq %rdi /* pt_regs->di */
pushq %rsi /* pt_regs->si */
pushq %rdx /* pt_regs->dx */
pushq %rcx tuichu /* pt_regs->cx */
pushq $-ENOSYS /* pt_regs->ax */
pushq %r8 /* pt_regs->r8 */
pushq %r9 /* pt_regs->r9 */
pushq %r10 /* pt_regs->r10 */
pushq %r11 /* pt_regs->r11 */
sub $(6*8), %rsp /* pt_regs->bp, bx, r12-15 not saved */通过汇编指令判断是否为
x32_abi。通过系统调用号,跳到全局变量
sys_call_table相应位置继续执行系统调用。
kernel space to user space
退出时, 流程如下:
- 通过
swapgs恢复 GS 值 - 通过
sysretq或者iretq恢复到用户控件继续执行。如果使用iretq还需要给出用户空间的一些信息(CS, eflags/rflags, esp/rsp等)
struct cred
Kernel用cred结构体记录进程的权限,每一个进程都有一个cred结构,这个结构保存了该进程的权限等信息(uid, gid等), 如果能修改某个进程的cred,那么也就修改了这个进程的权限。
源码 如下:
struct cred { |
内核态函数
相比用户态库函数,内核态的函数有了一些变化
- printf() -> printk(),但需要注意的是 printk() 不一定会把内容显示到终端上,但一定在内核缓冲区里,可以通过
dmesg查看效果 - memcpy() -> copy_from_user()/copy_to_user()
- copy_from_user() 实现了将用户空间的数据传送到内核空间
- copy_to_user() 实现了将内核空间的数据传送到用户空间
- malloc() -> kmalloc(),内核态的内存分配函数,和 malloc() 相似,但使用的是
slab/slub 分配器 - free() -> kfree(),同 kmalloc()
另外要注意的是,kernel 管理进程,因此 kernel 也记录了进程的权限。kernel 中有两个可以方便的改变权限的函数:
- int commit_creds(struct cred *new)
- struct cred* prepare_kernel_cred(struct task_struct* daemon)
从函数名也可以看出,执行 commit_creds(prepare_kernel_cred(0)) 即可获得 root 权限,0 表示 以 0 号进程作为参考准备新的 credentials。
更多关于
prepare_kernel_cred的信息可以参考 源码
执行 commit_creds(prepare_kernel_cred(0)) 也是最常用的提权手段,两个函数的地址都可以在 /proc/kallsyms 中查看(较老的内核版本中是 /proc/ksyms。
sudo grep commit_creds /proc/kallsyms |
一般情况下,/proc/kallsyms 的内容需要 root 权限才能查看, 若以非root权限查看将显示为0地址。
Mitigation
canary, dep, PIR, RELRO等保护与用户态原理和作用相同
- smep:
Supervisor Mode Execution Protection,当处理器处于ring0模式,执行用户空间的代码会触发页错误。(在 arm 中该保护称为PXN) - smap:
Superivisor Mode Access Protection,类似于 smep,通常是在访问数据时。 - mmap_min_addr: mmap_min_addr 控制着 mmap 能够映射的最低内存地址,而这个参数能够通过
/proc/sys/vm/mmap_min_addr这个文件来进行读写。系统中的任何用户都可以读这个文件,但只有root用户能够写这个文件。
CTF kernel pwn 相关
一般会给三个文件boot.sh, bzImage, rootfs.cpio
boot.sh: 一个用于启动 kernel 的 shell 的脚本,多用 qemu,保护措施与 qemu 不同的启动参数有关, 如下!/bin/bash
stty intr ^]
cd `dirname $0`
timeout --foreground 600 qemu-system-x86_64 \
-m 64M \
-nographic \
-kernel bzImage \
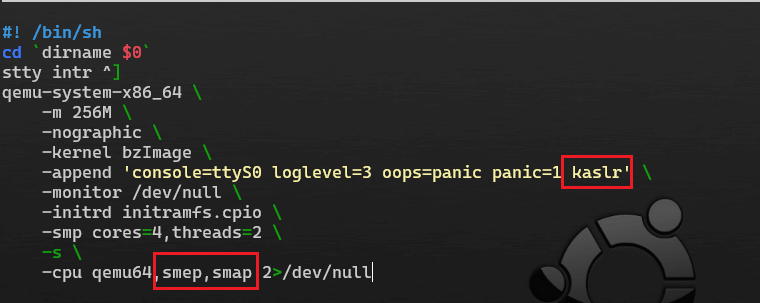
-append 'console=ttyS0 loglevel=3 oops=panic panic=1 nokaslr' \
-monitor /dev/null \
-initrd rootfs.cpio \
-smp cores=1,threads=1 \
-cpu qemu64 2>/dev/null, +smep解释一下 qemu 启动的参数:
-initrd rootfs.cpio,使用 rootfs.cpio 作为内核启动的文件系统-kernel bzImage,使用 bzImage 作为 kernel 映像-cpu qemu64 2>/dev/null, +smep,设置 CPU 的安全选项,这里开启了 smep-m 64M,设置虚拟 RAM 为 64M,默认为 128M- 其他的选项可以通过 –help 查看。
一般来讲, 可以在最后加上
-s或-gdb tcp::1234 -S使得我们可以使用调试进行连接调试。注意, 后者会使虚拟机启动时强制终端等待调试器连接。bzImage: kernel binaryrootfs.cpio: 文件系统映像*.ko: 有漏洞的驱动或模块, 可以使用IDA打开. 如果附件包中没有*.ko, 此时需要我们自己到文件系统中将其提取出来ext4: 将文件系统挂载到已有目录mkdir ./rootfs
sudo mount rootfs.img ./rootfs此时查看根目录下的
init或etc/init.d/rcS文件, 这时系统的启动脚本, 可以以此看到加载驱动的路径, 这时可以将驱动或模块拷贝出来
卸载文件系统
sudo unmount rootfs
cpio: 解压文件系统mkdir core
cd core
cp ../rootfs.cpio rootfs.cpio
cpio -i --no-absolute-filenames -F rootfs.cpio此时跟其他文件系统一样, 找到启动文件, 查看加载的驱动, 拷贝出来
vmlinux: 有时还会有vmlinux文件, 一般含有符号信息,可以用于加载到gdb中方便调试(gdb vmlinux),当寻找gadget时,使用objdump -d vmlinux > gadget然后直接用编辑器搜索会比ROPgadget或ropper快很多。没有vmlinux的情况下,可以使用linux源码目录下的scripts/extract-vmlinux来解压bzImage得到vmlinux(extract-vmlinux bzImage > vmlinux),当然此时的vmlinux是不包含调试信息的。本地写好 exploit 后,可以通过 base64 编码等方式把编译好的二进制文件保存到远程目录下,进而拿到 flag。同时可以使用 musl, uclibc 等方法减小 exploit 的体积方便传输。
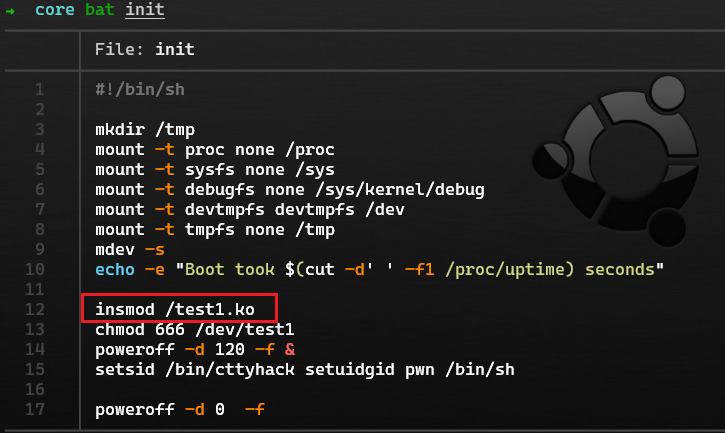
部分 Kernel 漏洞只影响低版本,高版本的 Kernel 已对脆弱的机制进行了一定程度的遏制乃至进行了消除,但是和 Glibc 相同,部分中低版本的内核仍有很高的用户量,因此我们对于低版本 Kernel 的漏洞研究并非是没有意义的,同时,在实际调试 Demo 时,请特别注意 Demo 漏洞影响的 Kernel 版本。
Linux Kernel 保护机制
KPTI: Kernel PageTable Isolation, 内核页表隔离KASLR: Kernel Address space layout randomization, 内核地址空间布局随机化SMEP: Supervisor Mode Execution Prevention, 管理模式执行保护SMAP: Supervisor Mode Access Prevention,管理模式访问保护Stack Protector: Stack Protector又名canary,stack cookiekptr_restrict:允许查看内核函数地址dmesg_restrict:允许查看printk函数输出,用dmesg命令来查看MMAP_MIN_ADDR:不允许申请NULL地址mmap(0,....),null pointer dereferences
KASLR、Stack Protector与用户态下的ASLR、canary保护机制相似。SMEP下,内核态运行时,不允许执行用户态代码;SMAP下,内核态不允许访问用户态数据。SMEP与SMAP的开关都通过cr4寄存器来判断,因此可通过修改cr4的值来实现绕过SMEP,SMAP保护。
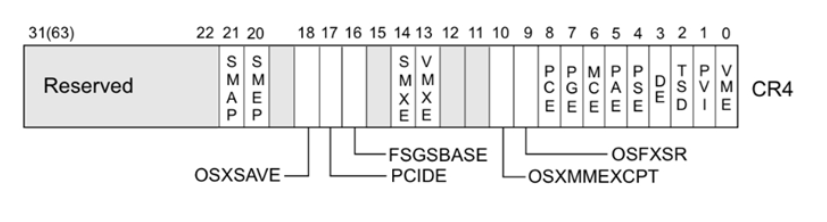
可以通过cat /proc/cpuinfo来查看开启了哪些保护:
/ $ cat /proc/cpuinfo |
KASLR、SMEP、SMAP可通过修改boot.sh来关闭, 方便我们调试(以下是 starctf2019-hackme的启动文件startvm.sh)
dmesg_restrict、dmesg_restrict可在rcS文件中修改:
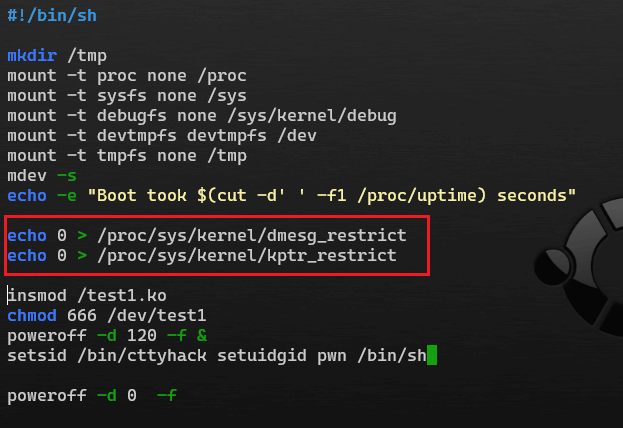
MMAP_MIN_ADDR是linux源码中定义的宏,可重新编译内核进行修改(.config文件中),默认为4k
Linux Kernel漏洞类型
指针
- 未初始化指针
- 未验证指针
- 已损坏的指针解引用
内核栈
- 栈溢出
- 栈破坏
内核堆
- 堆溢出
- UAF
- Unlink
整数
- 整数溢出
- 符号转换错误
逻辑漏洞
- 引用计数器溢出
- 缺失权限检查
- 检查使用时序不当
- 竞态条件
exp 上传脚本
这里搬运自【Pwn 笔记】Linux Kernel 调试文件总结
写 exp 的时候需要在当前目录下新建一个 poc 文件夹,把 c 文件和 c 程序都放在那里
普通用户
#!/usr/bin/env python |
root用户
#!/usr/bin/env python |






